2020年3月12日| 作者: 塔米·卡特(TAMMY CARTER)
發表於軍事嵌入式系統
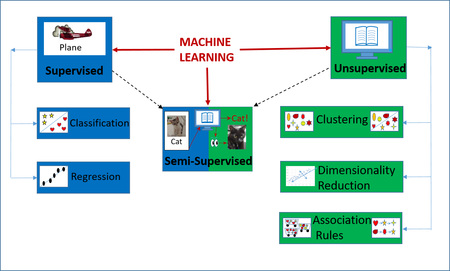
在我們正在進行的深度學習系列的最新專欄中,我們將考慮以下問題:“如何教機器學習?” 機器像人類一樣,從經驗中學習。 他們從圖像,文本或其他數據的輸入中進行觀察,然後尋找模式。 在機器遍歷數學層之後,它會根據給出的示例學習做出更好的決策。 決策輸出可以是連續的(例如,價格波動),二進制的(“是”或“否”)或分類的(例如,識別飛機,坦克,直升機或潛艇等)。 對於分類輸出,結果答案將是多個變量(例如,描述飛機的屬性),而不是單個變量。 機器學習應用程序的培訓環境將大致分為三大類之一:有監督的學習,無監督的學習或強化學習。 在本專欄中,我們將研究有監督和無監督學習,以及半監督學習的混合方法。 在本系列的下一篇專欄中,我們將考慮強化的機器學習環境。
描繪機器學習的不同分支的圖表由Curtiss-Wright的高級產品經理Tammy Carter提供。
監督學習:教我
由於它既是最容易理解的又是最簡單的實現,因此監督學習已成為最受歡迎的機器學習方法。 監督學習在輸入和輸出上都使用標記的數據,這使機器可以學習輸入和輸出之間的關係。 標籤是賦予數據中對象的標籤(或描述)。 可以將機器學習算法視為兒童,將標記的數據視為兒童用來學習的閃存卡。 給定特定的標記輸入,該算法能夠預測答案。 輸出標籤為算法提供反饋,以使其知道答案是否正確。 隨著時間的流逝,該算法能夠通過觀察來學習並發現數據中的模式。 發現模式之後,該算法即可處理先前未知的新輸入,並基於該輸入正確提供輸出。 可以將這種機器學習方法描述為心理學定義的“概念學習”的機器版本。
監督學習問題主要有兩種類型。 第一種問題類型使用分類算法來預測分類結果。 第二種類型使用回歸算法根據屬性之間的相關強度預測數字標籤。 對象識別和手勢解釋都使用分類算法。
假設任務是基於攝影圖像對飛機類型進行分類(或識別)。 第一步是考慮識別飛機所需的各種屬性。 由於可能的屬性數量很多,因此我們只關注翅膀。 機翼位置將是一個屬性,可以選擇頂部安裝,中間安裝或底部安裝。 機翼形狀可以是直的,後掠的,三角形或半三角形。 其他機翼屬性包括傾斜,錐度和機翼尖端形狀。 當然,這些只是機翼的某些屬性。 現在,想像一下標識其他屬性來描述引擎,機身和機尾等。為了使事情複雜化,大多數戰鬥機還可以根據其任務攜帶不同的彈藥,油箱或吊艙。 它變得更加複雜。 請記住,飛機分類必須在所有可能的觀察方面都有效,包括正面,側面,背面,不同的旋轉角度以及所有類型的天氣和背景。
在設計了飛機分類算法,訓練了模型並驗證了所需的準確性之後,現在可以使用分類器了。 該算法的準確性由正確分類的項目在所有預測中所佔的百分比來衡量。 送入圖像時,該算法將通過對每個屬性進行分類來處理該圖像,並返回最匹配該圖像屬性的飛機類型。 例如,該模型的收益率可以確定85%的確定性是該圖像是戰鬥機,而其他15%的確定性是一架空中戰鬥機。 用於對象識別的常見分類算法包括樸素貝葉斯(Naïve Bayes),邏輯回歸(logistic regression),支持向量機(Support Vector Machines/SVM)和k最近鄰(k-Nearest Neighbors / k-NN)。
監督機器學習的另一個子領域是回歸分析,它旨在對所選輸入特徵與連續輸出變量之間的關係進行建模。 如果變量可分配給最小值和最大值之間的任何值,則它是連續變量。 離散變量具有可數的可能值。 例如,一個人的確切年齡是一個連續變量,而按年數衡量的年齡是一個離散變量。 回歸預測問題的輸出通常會產生數量或大小的數據,而輸入可以是連續變量和離散變量的任意混合。 如何使用監督回歸的經典示例是基於一組屬性(例如,里程,年齡,品牌和位置)來預測二手車價格。 計時器系列的預測問題是另一個回歸問題,輸入變量按時間排序。
回歸問題的常見性能度量是均方根誤差(RMSE),它測量系統在其預測中產生的典型誤差。 可以對某些算法(例如決策樹/隨機森林)進行稍加修改,以進行分類和回歸。 有時,用戶可以通過處理數據來選擇使用分類還是回歸。 一種稱為離散化的數據處理方法將數量分成具有離散關係的多個離散倉。 例如,二手車價格可以分為三類:低於$ 10,000,$ 10,000- $ 20,000和超過$ 20,000。
有監督的機器學習嚴格控制輸入,輸出和培訓,這使定義培訓的目標和衡量成功度的錯誤的準確性變得容易。 例如,目標可能是確定地面移動目標是坦克,裝甲運兵車(APC)還是移動導彈發射器,其準確性為97%。
監督式機器學習還涉及某些折衷:一個折衷就是構建具有較高準確度百分比的模型需要大量數據。 由於人類必須在數據上粘貼標籤並糾正或刪除過程中的任何不良數據,因此這可能會變得很費力。 同樣,在監督式機器學習中,可能的輸出是預定義的,這意味著機器探索其他可能性並獲得對數據連接的新見解的能力受到限製或完全消除。
無監督學習:我是一名自學者
無監督學習,也稱為Hebbian學習的一種,本質上與有監督學習相反。 沒有標籤且沒有預定義的結果,執行無監督學習的機器將搜索數據中的基礎關係,例如隱藏的模式和結構。 在某些情況下,發現隱藏模式本身就是最終目標。 或者,用戶可以選擇算法來壓縮數據,通過相似性組織數據或檢測異常。 由於世界上絕大多數數據都是無標籤的,因此可以將數TB的數據處理為可用數據的算法將大大提高生產力。 根據數據及其屬性,無監督學習被認為是數據驅動的(與任務驅動的監督學習相對)。
無監督學習可分為三類算法:聚類,降維和關聯規則分析。 聚類以及密度估計(確定樣本集中數據的分佈)是無監督模型中最常見的算法類別。 例如,它用於客戶細分,幻想聯盟統計分析和犯罪分子的網絡概況分析。 在無監督聚類中,對像被分為幾組,其成員共享特定的相似性。 與監督算法不同,組沒有標籤,因此用戶必須確定集群代表什麼。 例如,該算法可能會根據軍用地面車輛是否具有履帶或車輪將其分類。 聚類對於無監督機器學習的重要性導致了眾多的聚類算法供用戶選擇。
這些算法包括:
· K均值:數據點聚類為K專有組
K-means: Data points are clustered into K-exclusive groups
· 層次聚類分析(HCA):數據點分為父聚類和子聚類
Hierarchical Cluster Analysis (HCA): Data points are separated into parent and child clusters
· 期望最大化(EM):一種在E-Step和M-Step這兩種模式之間循環的迭代方法
Expectation Maximization (EM): An iterative approach that cycles between two modes, E-Step and M-Step
-E-Step:估算每個未觀察到的變量的期望值
- E-Step: Estimates the expected value for each unobserved variable
-M步:使用最大可能性優化分佈參數
- M-Step: Optimizes the parameters of the distribution using maximum likelihood
與聚類有關的任務是降維,降維是從未標記數據集的混亂中提取相關信息,然後刪除任何不必要信息的過程。 隨著樣本和變量數量的數據集越來越大,在正確的方向指導模型變得越來越困難。 降維減少了數據的複雜性,使模型可以更快地運行,佔用更少的內存空間,並且在某些情況下,表現出更好的性能。
問題是如何在不丟失數據集中重要信息的情況下減小數據量。 主成分分析(PCA)是最常見的降維算法之一,它可以找到最能區分數據點的基礎變量。 主成分(PC)是數據點在圖表上沿其分佈最大的維度。 一台PC可以包含一個或多個變量。 如果大多數對象的特徵相同,則在表徵數據時沒有用。 例如,假設您要比較單一麥芽蘇格蘭威士忌。 這些特徵可能包括地區,成本,顏色,身體,泥炭含量,水果,鹽水等。查看PCA空間中的單一麥芽蘇格蘭威士忌,該威士忌將自然沿x軸上的六個地理區域聚集。 相比之下,來自坎貝爾敦(Campbeltown)和艾萊島(Islay)的蘇格蘭威士忌將煙熏味和煙熏味濃厚的泥炭,而斯佩賽德(Speyside)威士忌則帶有淡淡的煙熏味和混合的泥炭味。 低地和高地威士忌會更柔和,帶有更多水果風味。 鹽和煙熏屬性與位置有關,因此是多餘的。 將第二個PC的泥炭含量與水果味相結合,將在每個地理位置分組中傳播威士忌類型。 PCA在數據中找到可能的最佳特徵,包括能夠最好地匯總並允許其預測或“重建”對象的組合。
無監督機器學習的另一個基石是使用關聯規則學習來啟用預測分析。 關聯規則學習涉及用於發現屬性之間有趣關係的一系列技術。 這些關係可以為基於其他事件的發生進行預測和計算某些事件的概率提供基礎。 例如,雜貨店在以前的銷售中運行的關聯規則算法可能表明,購買薯片和燒烤醬的人也傾向於購買啤酒。 有了這些信息,商店經理可以設計一個包含所有這三種產品的封頂促銷。 兩種最流行的關聯規則學習算法是Apriori算法,一種使用上一個項目集查找下一組項目集的迭代方法,以及等價類聚類和自底向上的晶格遍歷(ECLAT)算法。 儘管Apriori算法的工作原理類似於廣度優先搜索,但ECLAT模仿了深度優先搜索,這使其效率更高。
與監督學習相比,使用無監督學習的機器面臨更多挑戰,因為它沒有預定義的結果和正確答案的反饋。 沒有“地面真理”,確定無監督算法的成功也將更加困難。 即使有這些限制,當不受約束地自行發現模式時,無監督算法也可以產生高質量的結果。 同樣,無監督學習也可以在未標記的數據集上進行,這是另一個優點,因為世界上大多數數據都是未標記的,並且對大量數據進行註釋的過程非常耗時且昂貴。
半監督學習:我會在朋友的幫助下獲得成功
半監督學習跨越了有監督和無監督學習之間的界限,它利用標記和未標記的數據進行訓練。 在世界上,經常存在一小部分被標記的數據,並被絕大多數未標記的數據包圍。 一個向父母和老師學習,同時也自己發現知識的小孩,是半監督學習的一個很好的例子。 假設孩子有一隻拉布拉多狗作為寵物,而父母告訴孩子該動物是狗(標籤)。 後來,當探訪一個擁有八哥犬寵物的親戚時,孩子可能會通過觀察現有的相似性(未標記的數據)成功地將長相迥異的動物識別為狗。
半監督學習的一些實際應用是語音分析和Internet內容分類,以及DNA和RNA序列分類。 帶標籤的數據有助於識別特定的組,並提示它們可能是什麼。 毫不奇怪,大多數半監督算法將監督算法和非監督算法結合在一起。 例如,無監督的受限玻爾茲曼機器可以堆疊形成無監督的深層信念網絡(DBN),然後使用有監督的學習網絡來調整最終系統。
本專欄旨在更好地理解有監督和無監督機器學習以及半監督機器學習的混合方法。 除了提供示例外,還引用了每種類別中使用的最常見算法,以及每種類型的機器學習的利弊。 在下一節中,我們將討論強化學習。 同時,您可以考慮購買一些薯片,一些美味的啤酒,啤酒和燒烤醬來進行週末燒烤,或者,也可以考慮進行一些無監督的單一麥芽蘇格蘭威士忌的品嚐。

Tammy Carter是Curtiss-Wright防禦解決方案的GPGPU和軟件產品的高級產品經理,具有OpenHPEC。 除了獲得計算機科學碩士學位外,她還在國防,通信和醫療領域設計,開發和集成實時嵌入式系統方面擁有20多年的經驗。